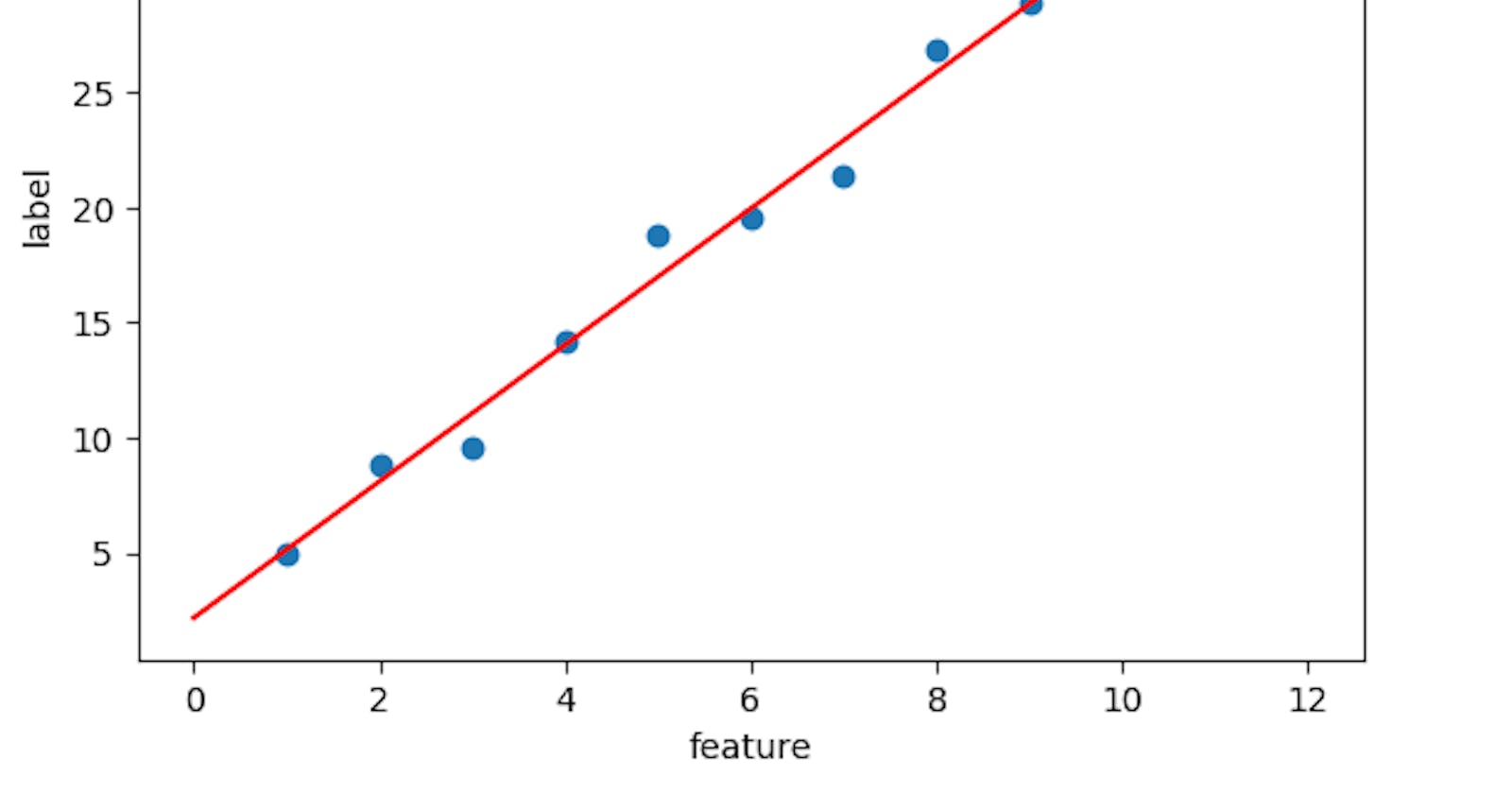
A Guide for Hyperparameter Tuning
Tuning Machine Learning Model Performance


You must experiment to find the optimum set of hyperparameters for the model. That said, here are a few rules of thumb from Google Machine Learning Course:
Training loss should steadily decrease, steeply at first, and then more slowly until the slope of the curve reaches or approaches zero.
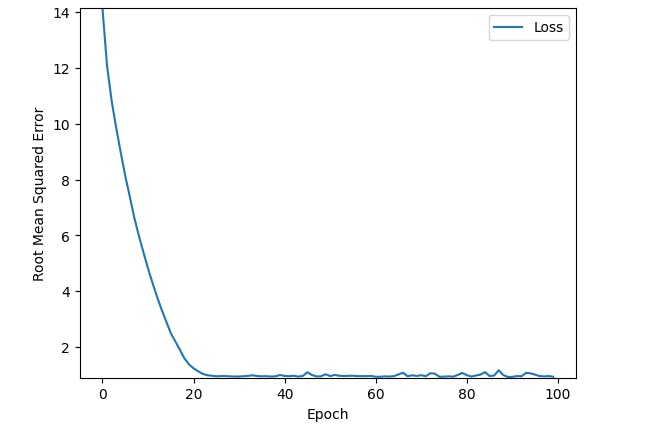
If the training loss does not converge, train for more epochs.
If the training loss decreases too slowly, increase the learning rate. Note that setting the learning rate too high may also prevent training loss from converging.
If the training loss varies wildly (that is, the training loss jumps around), decrease the learning rate.
Lowering the learning rate while increasing the number of epochs or the batch size is often a good combination.
Setting the batch size to a very small batch number can also cause instability. First, try large batch size values. Then, decrease the batch size until you see degradation.
For real-world datasets consisting of a very large number of examples, the entire dataset might not fit into memory. In such cases, you'll need to reduce the batch size to enable a batch to fit into memory.
Remember: the ideal combination of hyperparameters is data-dependent, so you must always experiment and verify.
Summary
The aim is to find the balance between learning rate and epochs while reducing the batch size (from the entire dataset).
With a low learning rate, the model will take forever to converge; with a high learning rate, the model will never converge.
With a low epoch, the model will underfit; with a high epoch, the model will overfit.
With a smaller batch size, the model will train faster but we have to watch out for underfitting.
Glossary
Root Mean Square Error: The average sum of the square of the difference between predicted and actual value calculated for labeled examples
Epoch: Number of iterations enough to account for the whole dataset E.g., for a dataset of 12, with a batch size of 4; one epoch will be equal to 3 iterations
Iteration: The period over which the parameters of the model (weight and bias) are updated based on the gradient. Determined by the batch size. E.g., for a batch size of 4, the parameters are updated after every 4 examples.
Converge: A model is said to have converged when the training loss is steady(no significant change in loss values) and is zero or near zero - refer to the graph)
Hyperparameters: A set of attributes of the model tweaked by the developer for better performance e.g., learning rate, epoch, batch size
References
Leave a like or comment if you found this piece helpful.